Run fast, debug easy: Exploring the synergy of Langium and LLVM
 Irina Artemeva
Irina ArtemevaYou have an idea for your own programming language. Eager to turn this idea into reality, you’ve wisely chosen Langium, easily got a parser and a IDE support, and now it’s time to make your language executable. Will it be fast? Debuggable? In this post, we explore how to address both these issues by integrating LLVM.
Run your language with Langium
You’ve parsed a program in your language and obtained its Abstract Syntax Tree (AST). To make it executable, Langium offers two ways:
- AST-based interpreter
- AST transformer (Transpiler)
- involves code generation: check out the tutorial to learn how to generate code using Langium
AST-based interpreter
Using this way, you traverse the AST of your program and tell the machine how to behave when it encounters each AST node. This allows you to formulate the semantics of your language, resulting in an interpreter. Since we are using Langium, which is written in TypeScript, it’s more convenient to implement the interpreter in TypeScript too. This way, the execution of your language becomes the execution of a TypeScript program that takes your program’s AST as an input.
 Run with Langium: Interpreter
Run with Langium: Interpreter
AST transformer (Transpiler)
With an AST transformer, you transform an AST. As opposed to interpreting with specifying how to execute your AST nodes, you translate them into another language, which is called the target language. Consequently, you delegate the semantics of your language to the target language, and the execution of your program is simply the execution of the program in the target language. Frequently you would choose a General Purpose Language (GPL) as the target language, but issuing machine code is also an option.
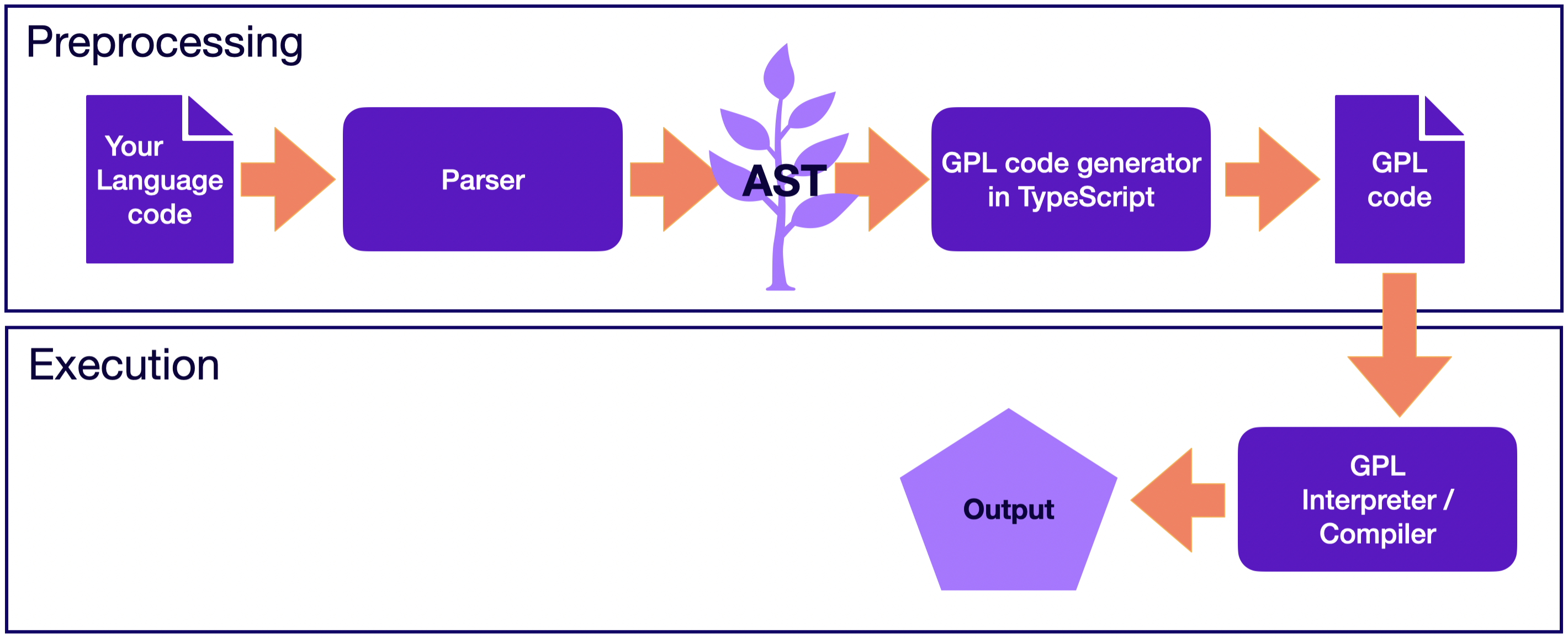 Run with Langium: Transpiler
Run with Langium: Transpiler
What is faster with Langium: interpreter or transpiler?
The performance of an interpreter and a transpiler depends on various factors such as the complexity of your language, the efficiency of the implementation, and the characteristics of the execution language. However, generally, a transpiler tends to be faster.
Firstly, what the execution phase entails. With interpretation, execution involves traversing the Abstract Syntax Tree (AST) of a program in your language. On the other hand, the transpiler is free from this overhead: it has already traversed your AST during preprocessing and simply executes the program in your target language.
Secondly, the separation of preprocessing and execution phases. In interpretation, these phases are typically not separated, meaning that pressing the ‘Run’ button will first parse your program to obtain an AST and then execute it by traversing. Conversely, with transpilation, you usually use two distinct commands: one to generate a program in the target language, and another to execute it. While this might not pose a significant challenge for single executions, it becomes critical when you need to execute your program multiple times with different inputs. In such cases, preprocessing during interpretation needs to be repeated each time the program is executed, which is not a drawback for transpilation.
Thirdly, consider the execution language in the context of Langium. While you have the freedom to choose any target language for transpilation, opting for TypeScript for interpretation makes sense (although you’re not limited to this choice, it’s the most straightforward option since Langium is written in TypeScript). This approach allows you to leverage the performance benefits of TypeScript for interpretation and the efficiency gains of the fastest target language for transpilation.
| AST-based interpreter | AST transformer (Transpiler) | |
|---|---|---|
| Performed Action | Execution (Interpretation) | Translation to the target language (Compilation) |
| Who defines the semantics | Your language itself | Delegated to the target language |
| Execution language | TypeScript (or any other language used by the interpreter) | Any that becomes the target language |
| Phase separation | Usually the preprocessing and execution phases are not separated | The pre-processing and execution phases are separated |
| Performance | May be lower: preprocessing is part of running; AST traverse at runtime | The same as if your program were written in the target language |
In conclusion: if performance is a priority, the transpiler option is recommended.
Transpiler: the best target language for performance
Choose your target language wisely, as the performance of your language entirely depends on it. While Assembly and machine code offer top performance, their low abstraction level may not be ideal. Many GPLs opt for C/C++:
- Well-proven as the target language
- code generation is much simpler than generating Assembly code
- look at the list of languages that compile to C/C++
- Fast
- designed to be close to the hardware, facilitates getting highly efficient machine code
- look at the performance of different languages on a program that plots the Mandelbrot set: C/C++ are at the top
- Platform independent
- C/C++ is portable, this makes your language portable “for free”
- Mature toolchain and large community
- well-supported compilers, debuggers, profilers
Looks like a perfect target language: the performance and all benefits of C/C++ will be achieved for your language! Let’s redraw the picture for the transpiler so that it uses C++.
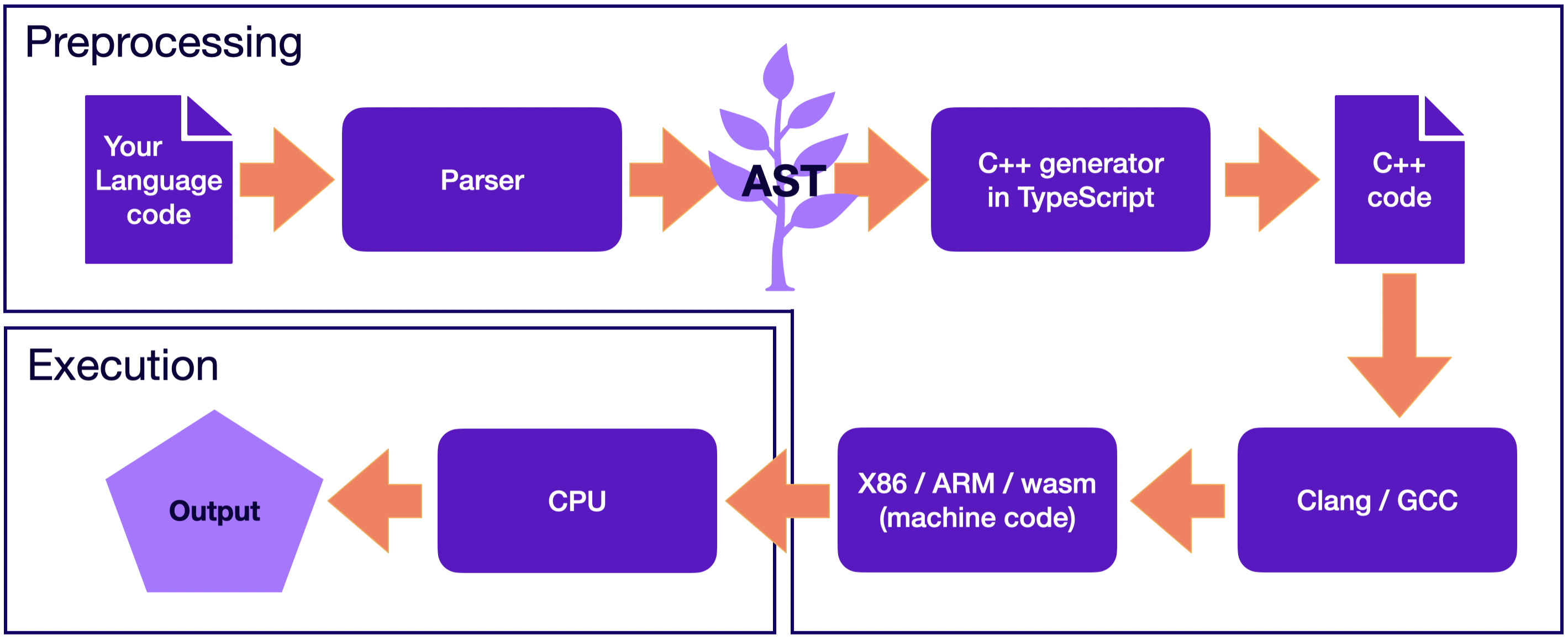 Run with Langium: Transpilation to C++
Run with Langium: Transpilation to C++
However, compiling to C/C++ isn’t the only popular approach for implementing your own language. Another promising alternative is to leverage LLVM. By tackling the challenge of making the language debuggable, we can better appreciate the advantages offered by LLVM.
Debugging problem
When we debug a program, we want to keep track of every variable update and every transition after each line is executed. However, the machine is not executing our program, but machine code that matches our program. Therefore, to make programs in your language debuggable, you need to map each instruction of your program to the corresponding instructions in the machine code.
For example, to debug a C++ program, you should compile it in debug mode. This will collect additional information about the C++ program in a special format, such as DWARF. This includes details about types, source locations, and variable locations, facilitating the creation of a mapping between the machine code instructions and the corresponding lines in your C++ program.
You have to do the same for your language. Using C++ as the target language means mapping each instruction from the program in your language to corresponding instructions in C++. Consequently, the C++ program undergoes additional mapping to machine code. See the problem? We’ll encounter an issue similar to what happens in a game of “Telephone”: multiple layers of mapping is more error prone than a single direct mapping.
 Debugging problem: Mapping debug information via an extra layer
Debugging problem: Mapping debug information via an extra layer
To address this issue, you can utilize LLVM infrastructure to create a compiler for your language. This approach offers performance comparable to C++, along with direct debugging support for your language, eliminating an extra layer of mapping to C++.
LLVM
Beforehand, this part refers to this wonderful source.
LLVM is a collection of modular and reusable compiler and toolchain components (e.g., assemblers, compilers, debuggers, etc.) used for developing custom compilers. The name “LLVM” originally stood for “Low Level Virtual Machine”, but is now just a brand for the LLVM umbrella project.
The idea behind LLVM is that compilers for different languages have a lot in common, which can be extracted into reusable libraries. To gain a better understanding of how these common parts look like, let’s explore the architecture of a three-phase compiler.
Three-phases of a compiler
A three-phase compiler architecture organizes the compilation process into three distinct phases whose major components are the frontend, the optimizer (the middle-end) and the backend.
 Three-phase compiler architecture
Three-phase compiler architecture
- Frontend
- responsible for the initial stages of the compilation process such as lexical, syntax, and semantic analysis, leading to the creation of an AST
- optionally converts the AST into a new representation for optimization
- Middle-end (Optimizer)
- focuses on optimizing the intermediate representation (IR) generated by the frontend
- enhances code efficiency and prepares it for the final code generation phase
- Backend (Code generator)
- generates code in the target language from the optimized IR
- tailors the code for a specific target architecture or machine
The division of the compilation process into phases allows for modularity, maintainability, and flexibility in the development of compilers. It enables developers to enhance or replace specific phases without affecting the entire compilation process.
With this design, porting the compiler to support a new source language requires implementing a new frontend, but the existing optimizer and backend can be reused. If these parts weren’t separated, implementing a new source language would require starting over from scratch, so supporting N targets and M source languages would need N*M compilers. Just imagine having to develop 9 compilers to support C++, Rust, and Haskell for X86, ARM, and RISC-V!
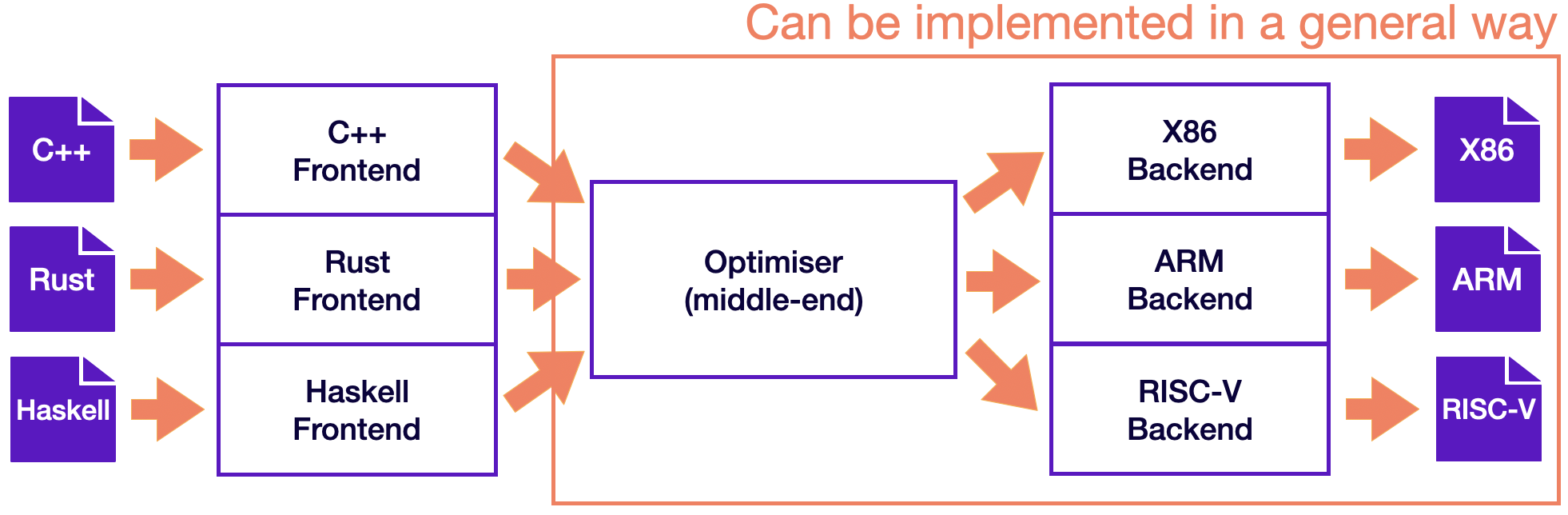 Three-phase compiler: optimizer and backend can be implemented in a general way
Three-phase compiler: optimizer and backend can be implemented in a general way
LLVM-based compiler
To decrease the amount of work, consider leveraging the optimizer and backend by developing an LLVM-based compiler. With this approach, you only need to implement the frontend to parse your program and subsequently translate it into LLVM IR. The LLVM IR can then undergo optimization passes, which can be chosen from a variety of options provided by LLVM or custom passes you write (see this tutorial for guidance). Finally, the optimized LLVM IR is processed by the backend to generate native machine code.
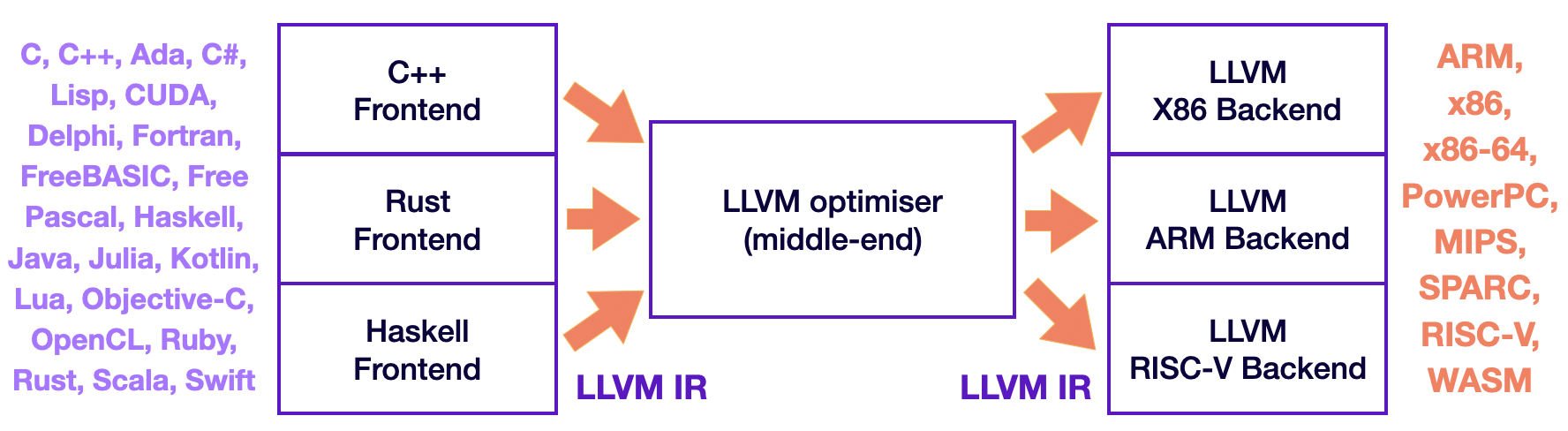 Three-phase compiler with LLVM
Three-phase compiler with LLVM
Your language with Langium and LLVM
By adopting this strategy for your language implementation, the primary focus narrows down to implementing the frontend with Langium, including translation to LLVM IR. With LLVM IR at hand, LLVM infrastructure can be leveraged for execution and optimization. In the picture below, you can observe how the Clang compiler, one of the LLVM components, is invoked to compile LLVM IR.
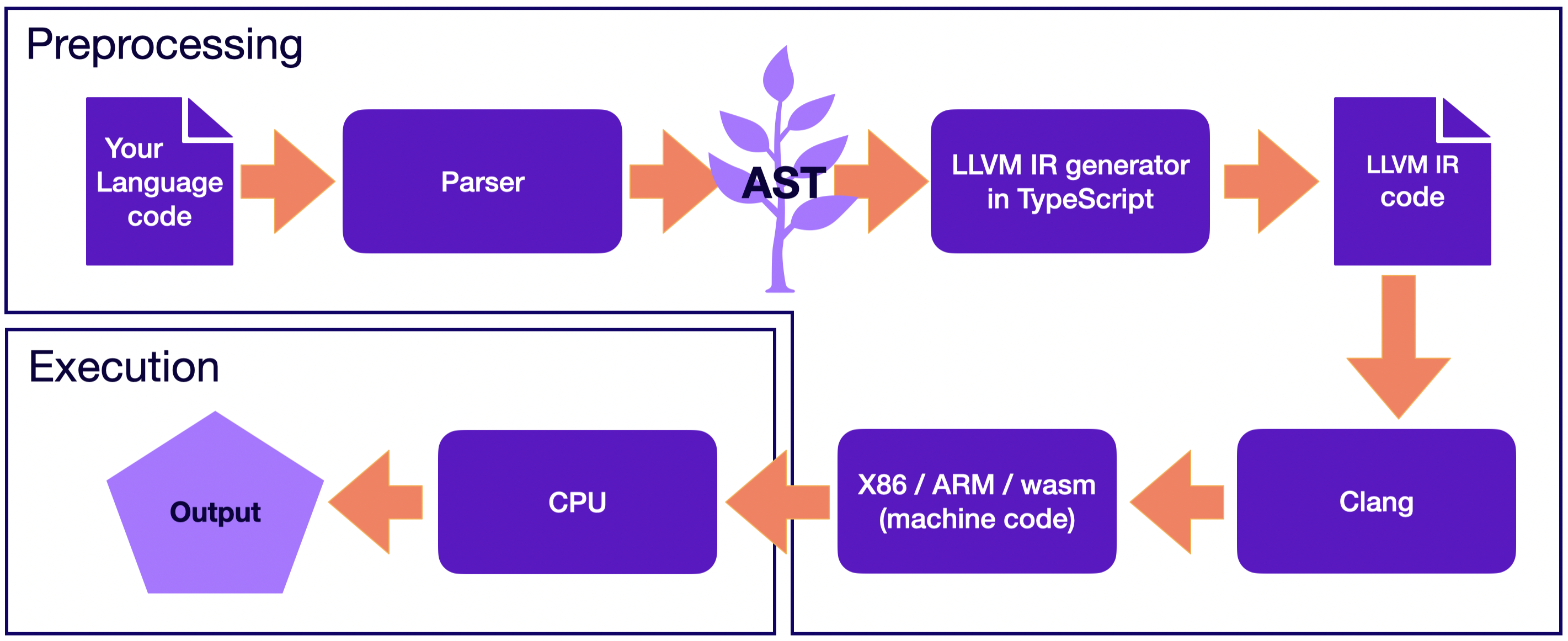 Run with Langium: Transpilation to LLVM IR
Run with Langium: Transpilation to LLVM IR
Debugging with LLVM
Meanwhile, making your language debuggable involves embedding debugging information into the LLVM IR program, which simply entails generating debugging information alongside LLVM IR. This crucially differs from transpiling to C++, as it eliminates the requirement for an extra mapping layer for debug information.
Finally, when debugging your program becomes necessary, you can seamlessly compile it in debug mode using Clang and then execute it with another LLVM component: the LLDB debugger.
Generating LLVM IR with Debug Information in TypeScript
At this juncture, we find ourselves facing a question: how to generate LLVM IR along with debug information? The LLVM API, designed primarily for C++ implementation, can be harnessed for the generation. Despite your language implementation relying on TypeScript through Langium, a seamless connection to C++ is achievable through the use of a LLVM binding library.
 LLVM IR generation in TypeScript: using of a LLVM binding library
LLVM IR generation in TypeScript: using of a LLVM binding library
Demo
Jumping into the future when everything is implemented, you might see a picture like this:
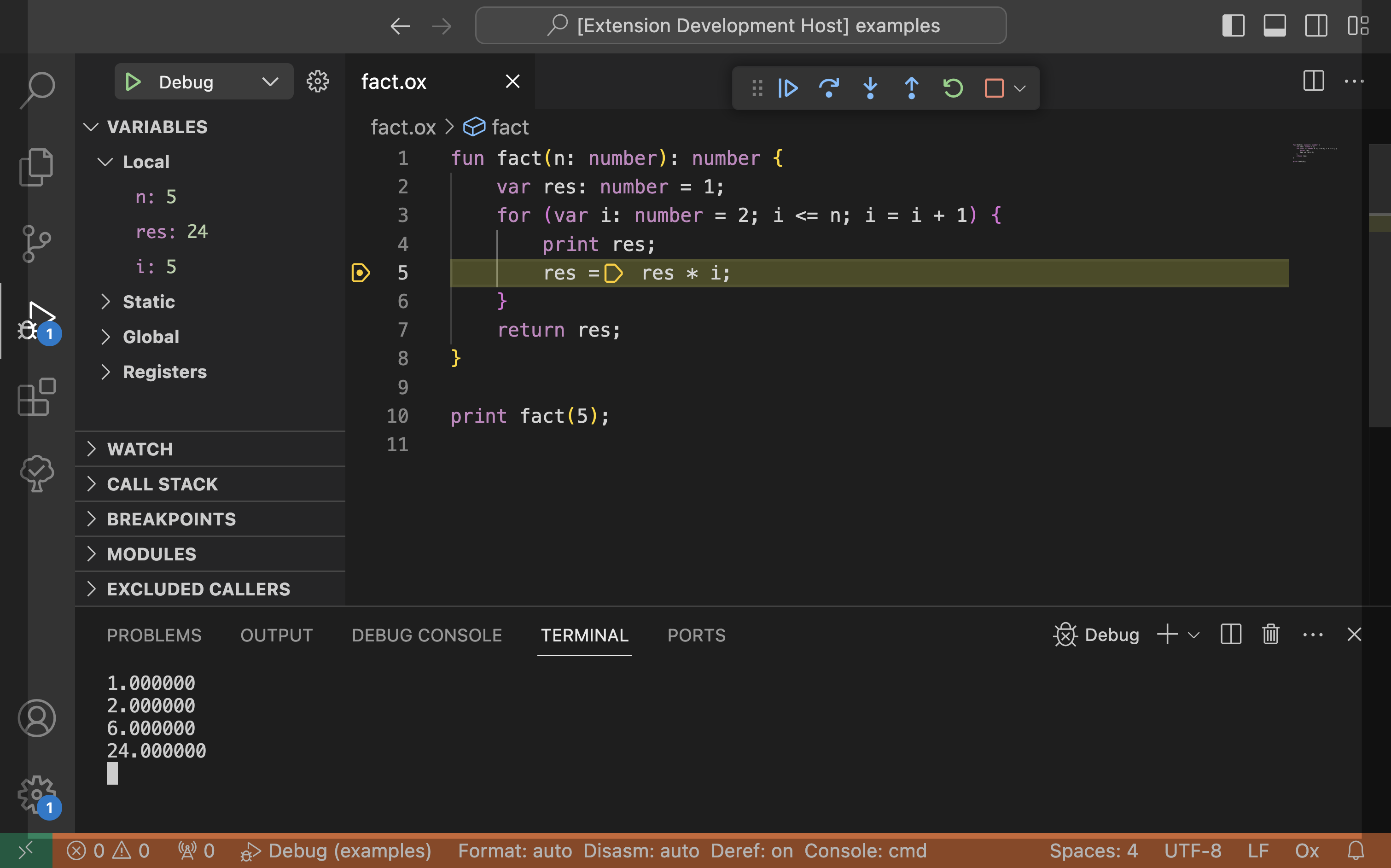 Demo: debugging own language
Demo: debugging own language
In the provided screenshot, the factorial program is written in own language, named Ox. Currently, we are running a real program in our own language in debug mode directly within VSCode!
While diving into every intricate detail exceeds the scope of this blog post, you are invited to explore the repository containing the Ox implementation for a more comprehensive understanding.
Conclusion
Whether you’re crafting the next programming paradigm or aiming to enhance the performance, Langium and LLVM will be your unwavering companions on this journey. May your language be elegant, execution be fast and debugging be seamless!
Read more about this topic



